ИИ плохо работает на длинной дистанции — такого сотрудника уже уволили бы
Исследователи Microsoft выяснили, что современные ИИ-модели и агенты пока плохо справляются с длинными рабочими задачами. Даже фронтирные модели начинают терять или искажать содержимое документов, если им поручить многошаговый процесс на десятки взаимодействий.

Исследователи Microsoft выяснили, что современные ИИ-модели и агенты пока плохо справляются с длинными рабочими задачами. Даже фронтирные модели начинают терять или искажать содержимое документов, если им поручить многошаговый процесс на десятки взаимодействий.
Авторы исследования «LLMs Corrupt Your Documents When You Delegate» решили проверить, насколько хорошо большие языковые модели справляются с тем, для чего их все чаще продвигают на рынке: автономной работой над сложными многоэтапными задачами.
Для теста исследователи создали бенчмарк DELEGATE-52. Он имитирует длинные рабочие процессы в 52 профессиональных областях — от программирования и бухгалтерии до кристаллографии и нотной записи. В одном из заданий по бухгалтерии модель получала документ с реестром операций некоммерческой организации и должна была разделить его на файлы по категориям, а затем снова собрать в один хронологический документ.
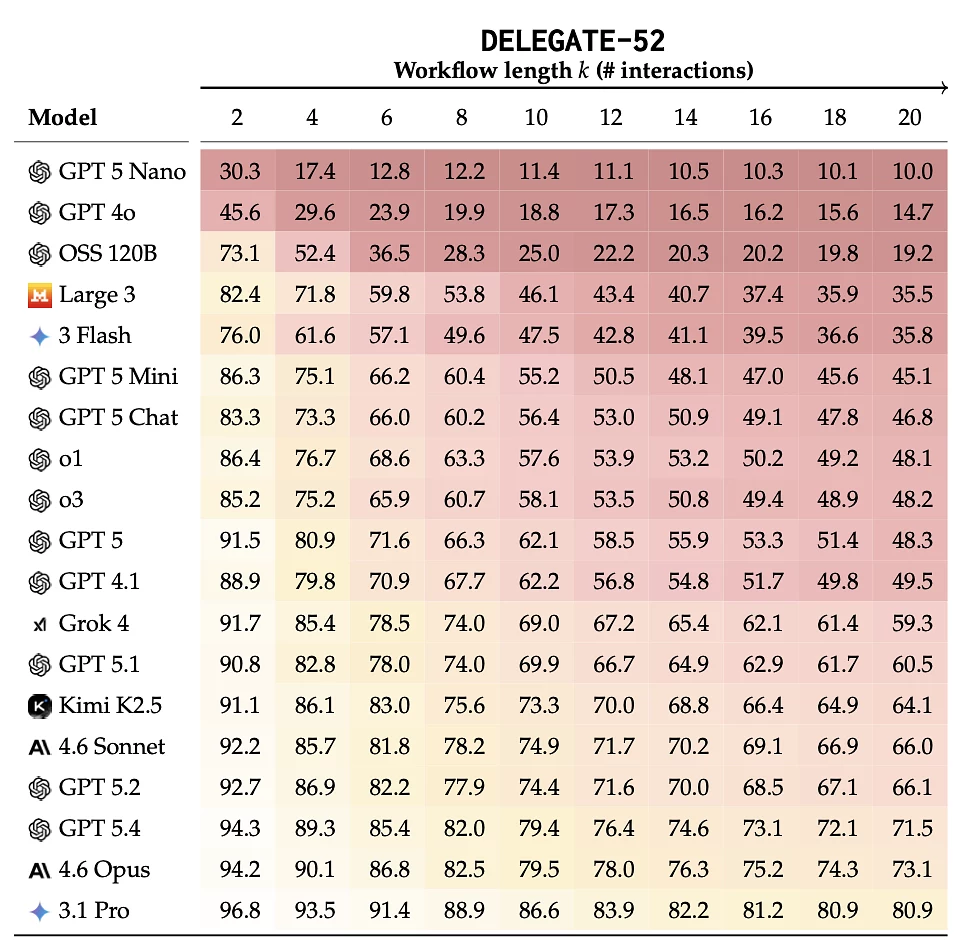
Результаты бенчмарка DELEGATE-52 для 19 языковых моделей при разной длине рабочего процесса. ИИ-модели теряют качество при длинных рабочих задачах: чем больше взаимодействий, тем сильнее деградация документа. Даже лидеры теста — Gemini 3.1 Pro, Claude 4.6 Opus и GPT-5.4 — заметно ухудшают результат после 20 шагов. Источник: arXiv.
Результаты оказались тревожными. «Наши выводы показывают, что современные LLM вносят существенные ошибки при редактировании рабочих документов: фронтирные модели Gemini 3.1 Pro, Claude 4.6 Opus и GPT-5.4 в среднем теряют 25% содержимого документа за 20 делегированных взаимодействий, а среднее ухудшение по всем моделям составляет 50%», — пишут исследователи.
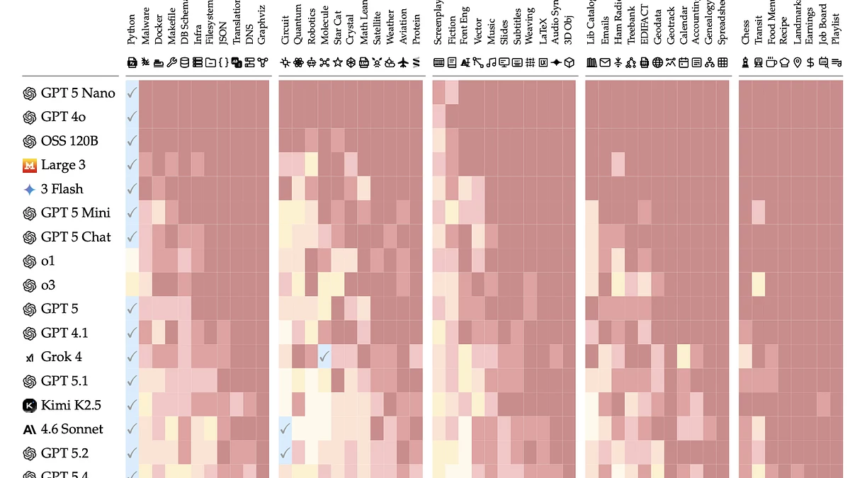
Лучше всего модели справлялись с программированием, хуже — с задачами на естественном языке. Чтобы считать модель готовой к конкретной профессиональной области, авторы установили порог: не менее 98% качества после 20 взаимодействий. Этому критерию соответствовала только одна область — программирование на Python.
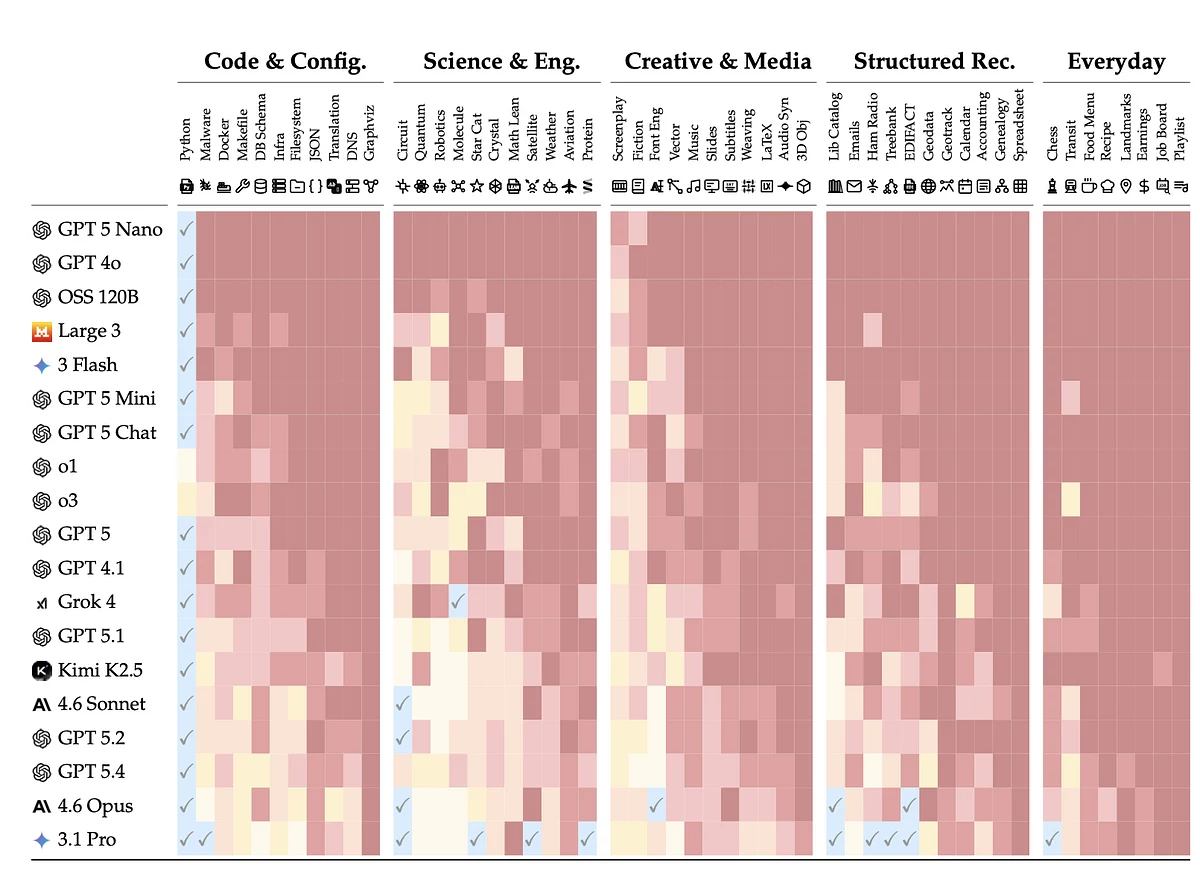
Итоговые результаты DELEGATE-52 после 20 взаимодействий по 52 профессиональным областям. Цветовая шкала показывает степень деградации документа: отметка ✓ означает готовность к делегированному рабочему процессу при результате ≥98%, а красные оттенки — существенное повреждение содержания. Источник: arXiv.
Во всех остальных областях модели оказались не готовы к делегированным рабочим процессам. «Разбивка итоговых результатов по областям показывает, что модели не готовы к делегированным рабочим процессам в подавляющем большинстве областей: в 80% наших симулированных условий модели серьезно повреждали документы — как минимум на 20%», — говорится в работе.
Интересно, что слабые модели чаще просто удаляли часть содержимого, а более сильные модели не столько удаляли, сколько искажали данные. Ошибки при этом не накапливались постепенно: часто они возникали резко, за один раунд взаимодействия, и сразу снижали результат на 10–30 пунктов.
«Более сильные модели — Gemini 3.1 Pro, Claude 4.6 и GPT-5.4 — не лучше избегают мелких ошибок; они откладывают критические сбои на более поздние раунды и переживают их в меньшем числе взаимодействий», — отмечают авторы.
Источник: devby.io







